在當今數字化時代,大數據的重要性日益凸顯,而大數據可視化技術則成為了將海量數據轉化為有價值信息的關鍵橋梁。
首先,數據挖掘技術是大數據可視化的重要支撐。它能夠從海量、復雜的數據中挖掘出隱藏的模式、趨勢和關系。通過聚類分析、關聯(lián)規(guī)則挖掘等方法,將原本雜亂無章的數據進行分類和關聯(lián),為可視化提供清晰的結構和有意義的信息。
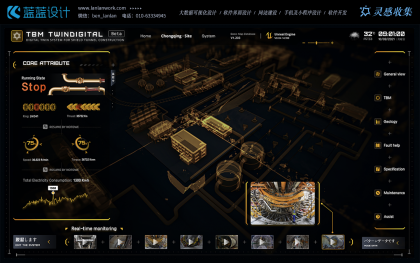
其次,數據倉庫技術也發(fā)揮著關鍵作用。它可以對來自多個數據源的數據進行整合、清洗和存儲,確保數據的一致性和準確性。這為大數據可視化提供了高質量的數據基礎,使得可視化結果更加可靠和有說服力。
再者,圖形處理技術在大數據可視化中不可或缺。例如,OpenGL 和 DirectX 等圖形庫能夠實現(xiàn)高效的圖形渲染,讓復雜的數據以流暢、逼真的形式展現(xiàn)出來。同時,WebGL 技術使得在網頁上進行高性能的 3D 可視化成為可能,為用戶帶來更加震撼的視覺體驗。
另外,基于 JavaScript 的可視化庫,如 D3.js、Echarts 等,為開發(fā)者提供了豐富的可視化組件和靈活的定制選項。它們可以創(chuàng)建各種類型的圖表,如柱狀圖、折線圖、餅圖等,并且能夠根據數據的動態(tài)變化實時更新可視化效果。
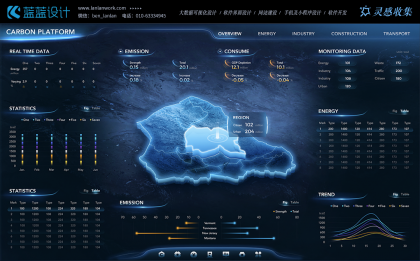
地理信息系統(tǒng)(GIS)技術在大數據可視化中也有著廣泛的應用。特別是當數據與地理位置相關時,GIS 能夠將數據在地圖上進行精準定位和展示,幫助用戶直觀地了解數據的空間分布和區(qū)域差異。
還有,虛擬現(xiàn)實(VR)和增強現(xiàn)實(AR)技術為大數據可視化帶來了全新的維度。通過創(chuàng)建沉浸式的虛擬環(huán)境或在現(xiàn)實場景中疊加虛擬信息,使用戶能夠以更加直觀和交互的方式與數據進行互動,深入挖掘數據背后的故事。
此外,數據流式處理技術,如 Apache Kafka 和 Flink,能夠實時處理和可視化不斷生成的數據流。這對于監(jiān)控實時數據,如金融交易數據、網絡流量數據等,具有重要意義。
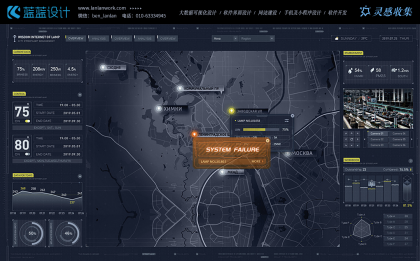
最后,機器學習算法在大數據可視化中也能發(fā)揮作用。例如,通過聚類算法對數據進行自動分類,然后以不同的顏色或形狀在可視化中展示,幫助用戶快速發(fā)現(xiàn)數據中的模式。
總之,大數據可視化技術多種多樣,它們相互配合,共同為我們呈現(xiàn)出豐富多彩、直觀易懂的數據視圖。隨著技術的不斷進步和創(chuàng)新,相信未來會有更多更先進的大數據可視化技術出現(xiàn),幫助我們更好地理解和利用大數據中的寶貴信息。












